
Kanonisk datamodel som fælles sprog
En kanonisk datamodel er i systemlandskabet det fælles sprog, som alle systemer kommunikerer igennem. På samme måde som engelsk kan fungere som fælles sprog, når en dansker skal tale med en ungarer. Da de (formentlig) ikke begge kan dansk eller ungarsk, så vælger man et fælles kommunikationssprog – engelsk. Danskeren formulerer sig først på modersmålet dansk, oversætter til engelsk og kommunikerer herefter til ungareren. Ungareren hører budskabet på engelsk og oversætter herefter i sit hoved til modersmålet ungarsk.
En kanonisk datamodel kan sammenlignes med engelsk; dvs. det fælles sprog, som kommunikeres. Hvis en dansker i stedet møder en rumæner, så skal han i princippet ikke ændre noget, hvis han ønsker at give samme besked. Han kommunikerer stadig på engelsk. Det, som ”udskiftes”, er oversætteren hos modtageren. Før blev der oversat fra engelsk til ungarsk. Nu oversættes der fra engelsk til rumænsk.
Den kanoniske datamodel i it-systemlandskabet fungerer tilsvarende, se følgende figur:
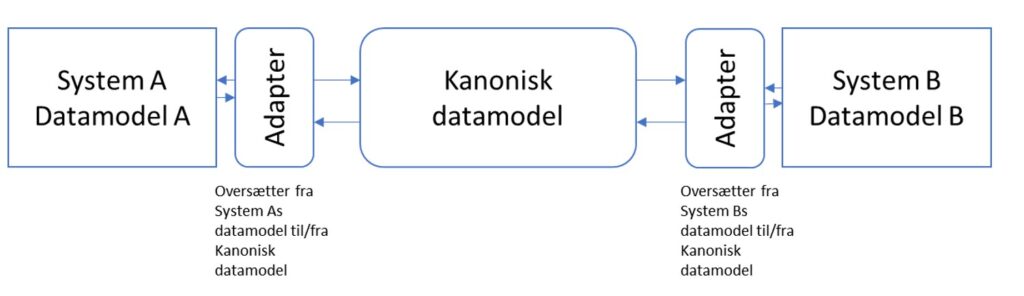
Kanonisk datamodel til semantisk afkobling mellem systemer
Mange organisationers arkitekturprincipper indeholder princippet om løse koblinger. I praksis betyder det, at it-systemer integreres via API’er i stedet for fx databaseforbindelser. Fokus er derfor ofte den tekniske afkobling.
Men et andet væsentligt aspekt er semantisk afkobling. Dvs. at de data, som udveksles mellem systemer, også er løs koblet eller afkoblet fra de pågældende systemer. Dette kan ske via en kanonisk datamodel, som vist på ovenstående figur.
I praksis betyder det, at udskifter man system B med system C på figuren, så er det kun adapteren mellem den kanoniske datamodel og system C, som skal ændres. I adapteren mappes attributterne mellem de to datamodeller, så de data, som modtages fra den kanoniske datamodel, transformeres til den datamodel, som anvendes internt i system C.
Kanonisk datamodel sikrer fælles definitioner af data
Den kanoniske datamodel vil også løse den kendte problemstilling med, at systemerne har forskellige definitioner af et begreb.
Så længe systemerne operer uafhængigt af hinanden, dvs. ikke interagerer, så er det nødvendigvis ikke et stort problem. Men hvis flere systemer med forskellige definitioner af samme begreb afleverer data til samme system, så er der stor risiko for fejl. Hvis data udveksles via den kanoniske datamodel, så er de defineret ens.
Problemet er illustreret i nedenstående figur.
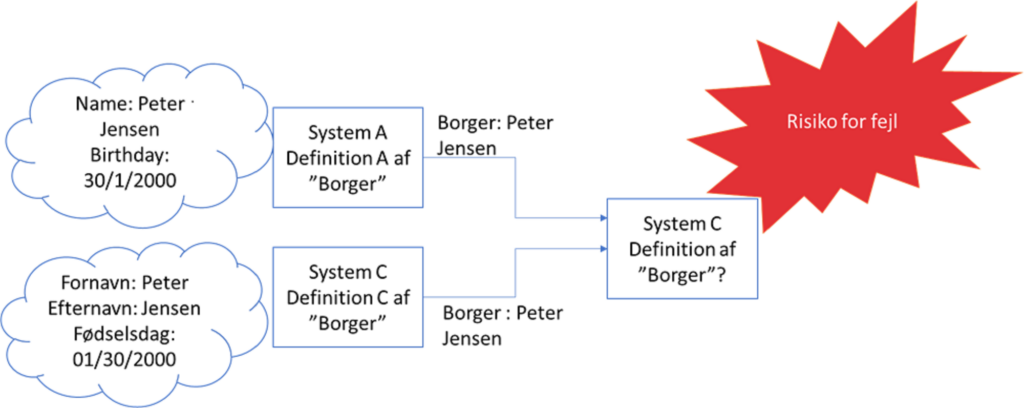
Kanonisk datamodel til datamigrering og business intelligence
Den kanoniske datamodel er også en stor fordel ved datamigrering og business intelligence (BI). Når du skal migrere data fra et system til et andet, så kan den kanoniske model anvendes som ”mellemstation” ved datakonverteringen. Ligeledes er den kanoniske model et særdeles effektivt redskab i kommunikationen til en evt. ny systemleverandør, som skal forstå jeres forretning for at kunne levere.
Endelig vil BI-området drage stor nytte af den kanoniske datamodel. Den største tidforbruger i BI-opgaver er transformation af data og sikre ens datadefinitioner. Ens datadefinitioner er en forudsætning for at kunne sætte data sammen eller sammenligne data. Hvis alle data har mapninger til den kanoniske datamodel, så er en stor del af dette transformationsarbejde allerede lavet. I den henseende er en kanonisk datamodel et skridt mod et masterdatakoncept, fordi der dermed kun eksisterer én definition af begreberne.
Udfordringer med en kanonisk datamodel
Det er en stor opgave at bygge en kanonisk datamodel. Det kræver involvering af både forretningen og personer med erfaring med datamodellering og datastandardisering. Ofte vil processen med at blive enige om begrebs- og datadefinitioner og begrebernes relationer være både tids- og ressourcekrævende.
Ligeledes vil den efterfølgende governance af modellen være ressourcekrævende.
It-udviklere mener også ofte (med rette), at deres agilitet nedsættes, fordi nye begreber skal gennem en governanceproces for at blive godkendt og tilføjet den kanoniske model. Der er derfor brug for en form for ”fast track” til midlertidig godkendelse af ændringer til modellen. Dette er en forudsætning for succes med den kanoniske datamodel over tid.
Men den kanoniske datamodel er alt krudtet værd.
Den tager tid at udvikle og implementere. Men du henter gevinsten i form af færre fejl, mere præcis datakommunikation og bedre BI.